Stanford Knowledge Systems Lab
December 15, 2000
HW#2: DAML Queries/Life Cycle
Overview
In this document, we propose a possible scenario for
five queries that might follow from DAML.
For the first three queries, we focus on information detailed quite
extensively in many of the submitted ontologies for homework assignment 1,
namely content related to DAML projects and personnel. The last two queries are motivated by our
services work and thus go beyond the current DAML ontology repository.
These queries follow in English but will later be
redefined in our query language:
1. Find the locations of researchers
funded by DAML.
2. Find the DAML participants who have a
research interest of knowledge representation.
3. Find the DAML funded projects whose
only tasks are producing ontology tools or services prototypes.
4. Does United Airlines (UAL) have a
flight from SFO to Boston?
5.
Find a
service that can book flights to Hawaii on an airline that Suzanne can collect
travel bonus points on.
Our task will be to develop a general query
answering architecture capable of supporting a query system and showing that
the above queries can be resolved within this system. In doing this, we will consider possible solutions to many of the
open questions concerning query languages, dynamic retrieval, caching,
translation, inference, and consistency while attempting to balance usability
with computational tractability.
Query Answering Architecture
Before we present our approach to query-answering, we first define a general query answering architecture (shown in figure 1) that subdivides the task of query-answering into an agent layer, a query processing layer, an inference layer, an ontology layer, and a semantic web layer. As well as defining the functions for each of these layers, we also define the interfaces between each layer, specifically the agent/query processor interface, the query processor/inference engine interface, the inference engine/ontology interface, and the ontology/semantic web interface.
While this is a general query answering architecture that one could instantiate with a wide variety of services and interface protocols, we will propose our approach in terms of services and protocols that have been developed and are used quite extensively at the Stanford Knowledge Systems Lab (KSL). We reiterate however that this is only one of many possible instantiations of the architecture and it is in fact our hope that other groups will propose alternatives for each layer and protocol according to their requirements and preferences. Alternately, one can also use our tools without adhering to the architecture that we present here.
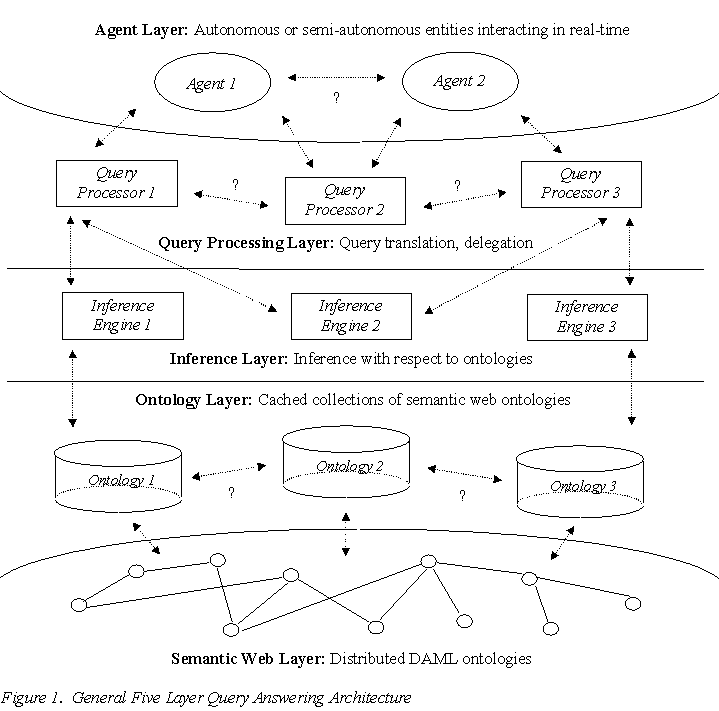
Layer Implementation
To define our architecture implementation, we begin
by defining the details of each layer starting at the level of the semantic web
and progressing upward toward the agent level.
Semantic Web Layer
The semantic web layer consists of a set of ontology
definitions (i.e. DAML or any other distributed ontology language) and instance
information potentially widely distributed over the Internet. Since the definition and implementation of this
layer is the subject of the DAML project, we will not further elaborate here.
Ontology Layer
Since the semantic web
layer is widely distributed and subject to the drawbacks of the Internet (i.e.
transient network outages and relatively slow retrieval times compared to
secondary or primary storage) it does not make sense for all query services to
interface in real-time with distributed web-based ontologies. On the other hand, some query services will
require retrieval on demand and it is therefore important to distinguish
between those services that can take advantage of cached ontologies and those
that cannot. Additionally, it would be
expected that some applications will be able to use major portions of cached
information and only have to make remote calls to distributed web ontologies
for a small amount of information.
For example, one cannot use cached data for queries
to on-line information services where the quality of up-to-date content is
extremely crucial to decision making (e.g. how a stock is performing at this
instant). Likewise, this is the case
for systems searching for reservations: Customers would not be happy with a
system making airline reservations based on information over a week old. For these and many other purposes, it only
makes sense to have data that is retrieved on demand. However, it is important to note that the amount of data that
one could expect on demand (especially in real-time) is much more limited than
that available from a repository of locally cached data. Furthermore, the opportunity to perform
inference on this data can be extremely limited if individual inference steps
themselves require queries.
On the other hand, a large portion of ontological
information such as geographical or historical knowledge is temporally stable
and can be reliably cached without information or consistency loss. This is the approach taken by most web
search engines and in most cases, content that is updated weekly is sufficient
for many purposes. The main advantage
of having information stored locally is that it allows for more complex and
computationally intensive methods of inference.
Since we focus here on relatively stable information
concerning research projects and personnel and furthermore since fairly complex
inference is important to many of our queries, the approach of caching semantic
web content seems the most pragmatic approach for our query answering
architecture.
Consequently, to complete the definition of this
layer we need to define the tools that will collect semantic web ontologies
into locally stored repositories. This
process can involve up to two steps: First, we may want to translate from the
web-based ontology language to an internal representation language that abstracts
away from the syntactic representation of the specific ontology language
used. And when collecting these
ontologies, we may also want to check them for internal consistency among other
things. Second, since we are gathering
information from a distributed set of ontologies likely defined and populated
by different sources, it can be
useful to have a method for merging
the terminology and instance data from these ontologies.
To achieve the first task for our implementation, we can use the Ontolingua knowledge representation system to internally represent semantic web content. Ontolingua is an expressive and general frame-based knowledge representation system developed at the KSL. Its advantages include the ability to read and export knowledge bases from a wide variety of languages including DAML, RDFS, OIL, KIF, OKBC, and CYC among many others. Additionally it also provides the functionality of an OKBC server and can therefore be accessed directly through an OKBC network connection. We may then also run an analysis on any ontologies that we have collected by loading them into the Chimaera ontology environment tool and running the analysis suite of tools.
To achieve the optional second task for our
implementation, we can use the Chimaera ontology merging tool to consolidate
the various ontologies imported into Ontolingua. Chimaera can interface with any OKBC compliant knowledge-base
server and is used to assist the user in merging multiple ontologies. We stress that it is not required to merge
the distributed ontologies. We have
found for applications that are likely to use inference, it may be beneficial
to merge ontologies and thus it is useful to have the support of an ontology
merging tool.
Query Processing Layer
The purpose of the query-processing layer is to
process the high-level query language passed from the agent layer. This layer should be capable of
disambiguating any references to terms used by the query engine. Additionally, it should be capable of
translating and delegating the required inference work for each query to the
appropriate set of inference engines.
Inference Layer
In this layer, we define a hypothetical inference
engine that interacts with ontologies defined in the ontology layer. The inference that is done here can have a
variety of types ranging from deduction, induction, and abduction to structural
subsumption. Consequently, it is
important not to restrict our view of inference or query answering to deductive
inference alone. Many other means of
inference are possible and potentially quite useful.
It is also likely that the inference layer may use a
hybrid architecture that utilizes a number of inferential approaches for
different portions of a task. We expect
to use the hybrid reasoning architecture implemented in JTP (Java Theorem
Prover) at Stanford, but other inferential brokers would be equally acceptable.
Agent Layer
For the purposes of our examples we will not be
elaborating on this layer other than to state that it is the origin of the
queries directed to the query-processing layer.
Interface Implementation
The point of defining the following protocol
specifications is simply to state that either there already exist interface
protocols that support our requirements, or that interface specifications are
needed.
Semantic Web/Ontology Interface
To implement the semantic web/ontology interface, we
simply need a mechanism that can import properly qualified ontologies from the
web into an intermediate knowledge representation system. Additionally, this intermediate knowledge
representation system should also able to export in the language used for
semantic web implementation. (As
mentioned earlier, we have already implemented DAML importing and exporting
capabilities for Ontolingua/Chimaera.)
Ontology/Inference Engine Interface
It is unlikely that all inference engines will be
integrated directly with the knowledge representation system. Furthermore, it is unlikely that this
approach would ever be taken since every query engine would have to implement
its own representation. Consequently it
makes sense that inference and representation are abstracted as two separate
entities.
For the ontology/inference engine interface in our
architectural instantiation, one potential interface is OKBC since Ontolingua
provides a full implementation of this generic knowledge interchange protocol.
Inference Engine/Query Processor Interface
Since the query processor takes care of term disambiguation and delegation of tasks to the inference engine layer, we expect that the interface language between these layers will be that of the specific inference engines utilized by the query processor.
Agent/Query Processor Interface
There are likely to be many interface protocols. We
will simply give two possible implementations for our query examples. It will probably be useful to have multiple
query languages defined so that the advantages and disadvantages of each query
language complement the others.
As a logical set of choices for our query language,
we could choose some form of a description logic, a SQL or OQL derivative, or
predicate logic. In our example
queries, we will demonstrate both a predicate logic formalism and a DAML-like
description logic-motivated formalism.
(One should additionally note from our query examples that we have
augmented these specifications with a few components analogous to SQL/OQL and
OKBC.)
The query language is used to specify queries to the
query engine but we have not yet stated how the results should be treated. The format of the answer may be obvious
given the query, e.g. if the query is asking for variable fillers in some
specified ordering then the query engine need only return a set or bag of the
variable fillers. If the query includes
multiple variables that need binding, then the answer may be a table (or list
of lists) of variable bindings.
Similarly, there could be other queries that whose answer is merely true
or false.
Architecture Summary
With each of the architecture layers and interfaces
now specified, we simply offer a quick review of our overall architecture
instantiation.
From the data side, data is imported from the
semantic web ontologies into a knowledge base (e.g. Ontolingua). Next a diagnostic/analysis tool (e.g.
Chimaera) may be applied to the ontology.
From this point, an ontology merging tool (e.g. Chimaera) can be
optionally applied to the knowledge base to merge the relevant content of
ontologies into a common terminology.
If no merging is done, all occurrences of ambiguous terms need some form
of resolution – that is likely to be by providing a precedence ordering of
ontologies from which to choose definitions of terms.
From the agent side, the agent sends a query to the
query processor which properly delegates the query to the inference layer. The inference engine then uses an interface
(e.g. OKBC) to access the cached ontologies (and dynamic web ontologies) and
perform any required inference. Once
the inference engine has completed, it returns its result as a labeled set to
the query processor, which performs any required packaging and passes the
result back up to the requesting agent.
Query Examples
With the query answering architecture defined, we
now provide implementations for the five queries stated initially. Following is a quick recap of these queries
in English:
1. Find the locations of researchers funded
by DAML.
2. Find the DAML participants who have a
research interest of knowledge representation.
3. Find the DAML funded projects whose
tasks include producing ontology tools or services prototypes.
4. Does United Airlines (UAL) have a
flight from SFO to Boston?
5.
Find a
service that can book flights to Hawaii on an airline that Suzanne can collect
travel bonus points on.
Before we translate these queries to our predicate
and DAML/description logic formalisms however, we need to elaborate on two
special concepts that will be useful to queries: context and inference
level.
Context defines the namespace for the terminologies
used in the query so that for example, a query involving the term ‘strike’ can
distinguish between workers striking or a pitcher in baseball throwing a
strike. One might say that if the
terminologies were fully qualified as in ‘http://baseball.org#strike’ then this
would not be an issue. However, it is
easier to reference the context of a term in general since this not only
identifies the term but also the closed-world semantics under which the term
can be reasoned about. Consequently, we
define a context argument for our queries that indicates the specific
ontologies (and implicitly their parents) to be used as references for the query
terms. If it is the case that two
context ontologies use overlapping terms then precedence will be given to the
ontologies according to the order that they are listed.
The second issue is that of inference level and
slightly delves into deeper topics such as trust, consistency, and belief
revision. Suppose that we have defined
an ontology that describes the class 'knowledge-representation'. Now assume that someone has built their own
ontology and extended the class of 'knowledge representation' with a subclass
of 'description-logic'. If this
information is not specified in our ontology then it could be of use during
inference. But what if someone else has
built their own ontology and extended the class 'knowledge-representation' with
a subclass of 'field-hockey'. Should we
use this information? Those literate in
knowledge representation and field hockey would know that the subclass
relationship does not exist. But how do
we distinguish between this ontology, which obviously contained incorrect information,
and the other ontology which defined valid and useful extensions? How do we denote authority and trust?
One possible answer is that the query should in
essence return a proof for every element of the dataset that it returns so that
the agent can make this decision.
However, this poses further questions and without a clear answer to the
problem we offer two simple workarounds.
The first workaround is to include an argument in our query for the
trust level of an ontology. That is,
all trusted ontologies should have some form of identification indicating
trust, perhaps through a secure identification certificate or more simply
through a compiled list of ontologies indicating trust level. Then, the query need only specify which
level of trust to require of the ontologies referenced in its queries
(:all-ontologies or :only-trusted).
However, there is one additional caveat involving unwanted revisions and
reference to ontologies whose version is known to be consistent. One solution which requires object
time-stamping would simply allow us to indicate that we only want to use
ontology components defined before some time point (when the ontology was
verified). This allows us to refer to
the last known stable version of an ontology without requiring the storage and
renaming of the same ontology multiple times for each of its revisions.
Given this additional machinery, we now rewrite our
queries under the assumption that they use concepts from the hypothetical
ontologies 'research-project-ont', 'knowledge-representation-ont',
‘services-ont’, and 'geography-ont'.
(i.e. Each symbol referenced in the following queries should exist in
one of the context-specified ontologies unless fully qualified. Other concepts could be specified but would
have to be fully qualified.)
First Query
To show the advantages and disadvantages of both
notations, we will provide a description for these queries in both a predicate
logic and a DAML-like description logic formalism. Our first example is written in predicate logic and involves
finding the locations (addresses) of researchers funded by the DAML project:
a) Predicate
Logic:
(retrieve
:comment |Find the locations of researchers funded by DAML|
:context (research-project-ont
geography-ont)
:use :only-trusted
:time 10-15-00
:return (?person ?addr)
:query (AND
(PERSON ?person)
(ADDRESS ?addr)
(EXISTS ?project
(AND (DAML-RESEARCH-PROJECT
?project)
(MEMBER-OF ?person
?project))))
In the above query, capitalized terms refer to
classes or relations and lowercase terms refer to individuals (this includes
variables).
Following is the description logic version of this
same query:
b) Description
Logic:
(retrieve
:comment |Find the locations of researchers funded by DAML \
Note: See our definition
of qualifiedBy below.|
:context (research-project-ont
geography-ont)
:use :only-trusted
:return person.name, person.has-address
:time 10-15-00
:query (AND PERSON
(qualifiedBy MEMBER-OF
DAML-RESEARCH-PROJECT))
The first issue to note is the return
structure. One can return the objects
satisfying the answer – i.e., the people and then let a user or program query
the object to find the parts of the information one is interested in. We included an additional notion of a return
field here that requires some post processing to obtain the values of those
roles directly. This actually could be
much more powerful than the standard FOL return since one could also return the
value restrictions instead of just returning the values. For example, if the address field is not
filled in but there is a value restriction associated with it, that restriction
could be returned.
The second issue to note is that we are using the
connotation of the 'qualifiedBy' term rather than the exact denotation from the
DAML specification. In DAML, a
qualification is itself a class and refers to the class, property, and
existential property value restriction.
In the above notation however, we are using the term 'qualifiedBy' in a
similar sense to imply that there exists some object referred to by the
qualified property which is a member of the given class. Consequently, our notation is simply
shorthand that can be used to infer the full specification of the qualification.
A third issue is one of role-paths. The qualification DAML-RESEARCH-PROJECT
could further be qualified with descriptions thus allowing chaining of
qualifications without the need for intermediate variables.
Between the two query methods, it is important to
note that the predicate logic based query method is slightly more expressive in
the fact that it can use arbitrary numbers of quantified variables but is more
difficult to write and understand. The
description logic provides for a more succinct query specification and as we
will see in the next query, more powerful inference due to structural
subsumption.
Second Query
Our second query involves finding DAML project
participants who have a research interest in knowledge representation. In the simplest sense, one could simply
search for any researcher who works on the DAML project and has a directly
stated interest in knowledge representation.
However, there are other potential methods for inferring someone’s
interest in knowledge representation and we also want to specify these possibilities. For example, if someone has published a
paper in a knowledge representation conference then we should be able to infer
that they have an interest in knowledge representation. Additionally, if someone has given an
invited talk, we may want to infer that they have an interest in knowledge
representation.
One can imagine placing these axioms in the
knowledge base to be inferred for any query.
However, we have to take into account that not everyone may agree on our
definitions. Also, it will not always
be the case that all appropriate axioms will be already input into knowledge
bases, thus it is important to be able to allow users to specify some inference
in the query rather than rely on the knowledge base to contain all inferential
information. It would be easy to specify this query assuming that the query is
just doing a database lookup for researchers who already have the research
interest mentioned. Thus, we focus on
the case where the query needs to specify some inferential capability in it.
1. Predicate Logic
(retrieve
:comment | Find the DAML participants who have a research \
interest of knowledge
representation |
:context (research-project-ont
geography-ont)
:use :only-trusted
:time 10-15-00
:query (AND
(PERSON ?person)
(EXISTS ?project
(DAML-RESEARCH-PROJECT
?project)
(MEMBER-OF ?person
?project)
(EXISTS ?interest
(OR
(AND
(KNOWLEDGE-REPRESENTATION ?interest)
(HAS-RESEARCH-INTEREST ?person ?interest))
(EXISTS ?conf
(AND
(KR-CONFERENCE
?conf)
(OR
(EXISTS ?pub)
(AND
(PUBLICATION ?pub)
(IN-CONFERENCE ?pub ?conf)
(HAS-PUBLISHED ?person ?pub)))
(EXISTS ?talk)
(AND
(RESEARCH-TALK ?talk)
(INVITED-TALK ?talk ?conf)
(GAVE-TALK ?person ?talk))))))))
In this case, the first order logic query is rather long compared to the description logic query that follows. Additionally, note that this query does not capture all of the answers, thus it really needs to have two additional rule specifications. For instance, what if a person has no directly stated interest in knowledge representation but rather a DAML qualifiedBy specification stating that at least one of the person’s interests is in knowledge representation? Also, if a person has no stated interest but has a DAML restriction on research interest stating that all of their interests are in the class KNOWLEDGE-REPRESENTATION (or a subclass of KR), then these people should also be returned. Unless this can somehow be inferred from the deductive machinery underlying the above query, this case would be missed.
Following is the description logic version of this
query:
b) Description
Logic:
(retrieve
:comment |Find the locations of researchers funded by DAML \
Note: See our definition
of qualifiedBy below.|
:context (research-project-ont
geography-ont)
:use :only-trusted
:time 10-15-00
:query (PERSON
(AND
(qualifiedBy MEMBER-OF
DAML-RESEARCH-PROJECT)
(OR
(qualifiedBy
HAS-INTEREST KNOWLEDGE-REPRESENTATION)
(qualifiedBy HAS-PUBLISHED
(AND PAPER
(qualifiedBy IN-CONFERENCE KR-CONFERENCE))
(qualifiedBy
GAVE-TALK
(AND TALK
(qualifiedBy INVITED-TALK KR-CONFERENCE)))))
One will note that this query manages to express the
same content as the predicate logic based query yet in a much more succinct
format. Additionally, through
subsumption inference, this specification also catches the case where no direct
interest in knowledge representation was stated but can be inferred from a
qualification or restriction specified in DAML. Consequently, given the advantages of a description logic
representation, we will be using only the description logic version of the
query for the third example.
Third Query
In this query, our goal is to find the DAML funded
projects that are producing ontology tools or services prototypes. This query shows the integration of a number
of features of the DAML language and their composition to form an object
description.
a) Description
Logic:
(retrieve
:comment | Find the DAML funded projects whose tasks \
are producing ontology
tools or services prototypes. |
:context (research-project-ont)
:use :only-trusted
:time 10-15-00
:query (PROJECT
(AND
(FUNDED-BY ‘daml) % A
simple slot-filler instance check
(OR
(qualifiedBy HAS-TASK
(AND TASK
(qualifiedBy
HAS-PRODUCT ONTOLOGY-TOOLS))))
(qualifiedBy HAS-TASK
(AND TASK
(qualifiedBy
HAS-PRODUCT SERVICE-PROTOTYPES)))))
We see that a description logic formalism succinctly
captures the query content in a compact and readable format. The predicate logic formalism yields queries
that can be long and require a fair amount of deductive machinery to catch all
subsumption cases (as we saw in the second query). However, the predicate logic formalism does have the distinct
advantage that it is more expressive than a description logic. It also may be
natural for certain portions of the population who prefer to read and write
logic. Consequently, whether one decides to use one formalism over the other
ultimately comes down to a question of expressivity versus ease of expression.
Fourth and Fifth Queries
The
previous three examples illustrated queries over knowledge that has been
expressed in the current DAML-ONT language and disseminated in Homework
Assignment 1. The queries were
expressible in DAML-ONT as well as in predicate logic and description logic, as
we demonstrated above. As we model more
complex relationships between entities on the web, the need for a more
expressive semantic web markup language becomes apparent. Much of this additional expressive power
will ideally be captured in DAML-L, which is in the process of development. If DAML-L does not satisfy all our
representational needs, we maintain the option of developing ontologies (i.e.,
logical theories) in more expressive languages (L), such as a sorted
first-order logic with equality, importing DAML ontologies into this more
expressive language L, and then
querying the resultant L
ontologies. This methodology is
consistent with the Query Answering Architecture illustrated in Figure 1.
Queries
4 and 5 adopt such a methodology. We
assume the existence of ontologies in first-order logic, and provide two queries
that we feel might be typical of queries for web services. They were conceived to illustrate two
points:
1)
While
DAML-ONT is sufficient to express a number of relationships between entities on
the web, it often does so in a verbose and awkward way. There is a need to define further constructs
within the DAML-ONT language to facilitate the encoding of notions that are
commonly used in even simple knowledge representation languages. N-ary relations are one such example. Adding such constructs does not technically
require extending the expressive power of the language, but merely provides
syntax to facilitate usage of the existing language. Some of these constructs can be implemented to improve the
efficiency of reasoning, as in the case of sorts, as evidenced by SRI’s theorem
prover, SNARK.
2)
There
are certain relationships that are compelling for the web that simply cannot be
expressed in DAML-ONT and that require the expressive power of first-order
logic with equality.
On the complexity of queries
The
homework assignment requested that we provide queries of roughly increasing
complexity. The queries we provide in
the next two examples do not appear to be complex in and of themselves, and
indeed Query 4 is no more complex than the previous queries expressible in
DAML-ONT. What can make a query complex
is the inference required to answer it, and this is a function not only of the
query language that is used, but also of the language in which the knowledge
being queried has been expressed. As a
straightforward example, we might have a query that asks whether a particular
American airline flies to San Francisco.
If the knowledge is represented in a table of American airlines and
destinations, then the so-called inference engine (in our Query Answering
Architecture) might be a simple table look-up.
If instead the knowledge is stored in a first-order logic axiom that
says all American airlines fly to San Francisco, then the inference engine required
for the exact same query might be a first-order logic theorem prover. Note that “more complexity” is not
synonymous with “less efficient.”
Fourth Query
Query
4 is a very simple query that illustrates point 1 above. The query is expressible in DAML-ONT, but
the syntactic sugar of allowing n-ary relations enables us to express the query
more parsimoniously in either predicate logic or description logic. The corresponding DAML-ONT query would be
much more verbose. The ontologies
underlying this query are in first-order logic.
Does United Airlines (UAL) have a flight from SFO to Boston?
a) Predicate
Logic:
(retrieve
:comment |Does UAL have a flight from SFO to Boston|
:context (services-ont)
:use :only-trusted
:time 10-15-00
:return True/False
:query (EXIST ?dtime ?atime ?price
(HAS-FLIGHT ‘ual ‘sfo ‘boston ?dtime ?atime ?price))
)
Solely for comparative purposes, note that the
DAML-based description logic version of this query requires a mapping of the
above query into purely binary relations:
b) Description
Logic:
(retrieve
:comment |Does UAL have a flight from SFO to Boston \
interpret as true if any
flights are returned|
:context (services-ont)
:use :only-trusted
:time 10-15-00
:query (AND FLIGHT-DATABASE-ENTRY
(USES-AIRLINE ‘ual)
(HAS-FLIGHT-ORIGINATION
‘sfo)
(HAS-FLIGHT-DESTINATION
‘boston)
)
Fifth Query
Query 5 illustrates a query that one could imagine
posing to the semantic web. It requires
the definition of notions within the ontology that are beyond the expressive
power of DAML-ONT, and indeed of description logic.
Find a service that can book flights to Hawaii on an
airline that Suzanne can collect travel bonus points on.
Predicate
Logic:
(retrieve
:comment |Find a service that can book flights to Hawaii on an airline
that Suzanne can collect
travel bonus points on.|
:context (services-ont suzanne-ont)
:use :only-trusted
:time 10-15-00
:return (?service ?capability)
:query (EXIST ?service
?capability
(AND (service ?service)
(capability ?service ?capability)
(bookAirlineTicket ?capability)
(bookTicket ‘company ?airline)
(valid-param ?capability ‘destination
‘hawaii)
(travel-bonus-member ‘suzanne ?airline))
)
Tools Wishlist
Although we have developed (or are in the process of
developing) many of the tools that would be needed to implement the above
queries, a tool that could perform query translation in the query processing
layer of our architecture would be useful.
Such a tool would need to take a fairly general query specification
language (likely distinct from any DAML ontologies) and attempt to map the
terminology and specification into a language more easily processed by the
query engine (i.e. a description logic, first order logic, SQL/OQL, or other
query language formalism). We also
provided previous input to Mike Dean on some tools both for the Wishlist and
for the tools in progress list.
Lessons Learned
Following are some of the deficiencies in DAML-ONT or other general lessons that we have discovered while completing this homework assignment:
· The ability to express DAML content concerning meta-individuals (classes that are themselves instances of another class) would be useful and eliminate the need for instance artifacts. For example, the method used to identify people interested in knowledge representation in the first two queries relied on the existence of an instance of ‘knowledge representation’ or one of its subclasses as a slot-filler for ‘has-interest’. However, it would be much more natural to directly check that ‘knowledge-representation’ or one of its subclasses is a slot-filler for this property. In this sense, the value restriction of ‘has-interest’ could be ‘research-field’, and the instances of ‘research-field’ could be ‘knowledge representation’ (itself a class) and its subclasses. Using such meta-individuals yields a more natural representation when the object instances of a property themselves have subclasses. Ontolingua and CycL are existing examples of languages providing meta description capabilities.
· The specification of ‘qualifiedBy’ and ‘restrictedBy’ in DAML are somewhat difficult to deal with (especially in queries) due to their specification as a set of binary relations. It would be useful to have either higher arity relations or some presentation syntax that could be easily reduced to binary relations. The presentation syntax available for OIL would be an appropriate candidate and in fact is similar to what we used in some of our queries. DAML+OIL will help minimize this problem.
· Since definitions of concepts (such as research interest) can vary from one user to the next, it is important to realize that it can often be more useful to place definition requirements in a query rather than in a knowledge base. This yields an equivalent query but prevents the specification of axiomatic knowledge which conflicts with another user’s definition. It is thus important to be able to express some sort of axiomatic information in both the query and in the knowledge base.
· As we model more complex relationships between entities on the web, the need for a more expressive semantic web markup language becomes apparent. Much of this additional expressive power will ideally be captured in DAML-L, which is in the process of development. If DAML-L does not satisfy all our representational needs, we maintain the option of developing ontologies (i.e., logical theories) in more expressive languages (L), such as a sorted first-order logic with equality, importing DAML ontologies into this more expressive language L, and then querying the resultant L ontologies
· While DAML-ONT is sufficient to express a number of relationships between entities on the web, it often does so in a verbose and awkward way. There is a need to define further constructs within the DAML-ONT language to facilitate the encoding of notions that are commonly used in even simple knowledge representation languages. N-ary relations are one such example. Adding such constructs does not technically require extending the expressive power of the language, but merely provides syntax to facilitate usage of the existing language. Some of these constructs can be implemented to improve the efficiency of reasoning, as in the case of sorts, as evidenced by SRI’s theorem prover, SNARK.
·
There
are certain relationships that are compelling for the web that simply cannot be
expressed in DAML-ONT and that require the expressive power of first-order
logic with equality.
·
It
would be useful to be able to make DAML-ONT extensible with a capability of
adding new functions. Query 5’s notion
of valid-param may be an example of such a function. Other examples of such needs can be seen when applications need
to perform some kind of optimization choice.
CLASSIC’s test function could provide a model for such extensible
capabilities.
·
The
“complexity” of a query can be measured many ways including how complex it is
to write and how complex the reasoning required to answer it. The latter is a function not only of the
query language that is used, but also of the language in which the knowledge
being queried has been expressed. As a
straightforward example, we might have a query that asks whether a particular
American airline flies to San Francisco.
If the knowledge is represented in a table of American airlines and
destinations, then the so-called inference engine (in our Query Answering
Architecture) might be a simple table look-up.
If instead the knowledge is stored in a first-order logic axiom that
says all American airlines fly to San Francisco, then the inference engine required
for the exact same query might be a first-order logic theorem prover. Note that “more complexity” is not
synonymous with “less efficient.”